Wstęp do pakietu ‘climate’ (PL)
Bartosz Czernecki, Arkadiusz Głogowski, Jakub Nowosad
2026-07-13
Source:vignettes/articles/pl.Rmd
pl.RmdGłównym celem pakietu climate jest zapewnienie wygodnego i programowalnego dostępu do danych meteorologicznych i hydrologicznych z publicznie dostępnych repozytoriów, w tym m.in.:
Instytut Meteorologii i Gospodarki Wodnej - Państwowy Instytut Badawczy (IMGW-PIB)
OGIMET (ogimet.com)
University of Wyoming - dane atmosferyczne dla radiosondaży (http://weather.uwyo.edu/upperair/).
Funkcje
Pakiet climate składa się z kilku głównych funkcji:
- Dane meteorologiczne
-
meteo_ogimet - Umożliwia pobieranie godzinowych i dobowych danych meteorologicznych ze stacji meteorologicznych nadających depesze SYNOP (FM-12) które są udostępnione w serwisie ogimet.com. Każda stacja meteorologiczna (synoptyczna) pracująca w ramach World Meteorological Organization (WMO) udostępnia swoje dane w ramach serwisu od ok. 2000 roku
- stations_ogimet - Umożliwia uzyskiwanie współrzędnych geograficznych, położenia stacji nad poziomem morza oraz identyfikatora WMO i nazwy stacji dla kraju określonej przez użytkownika; opcjonalnie wykreśl wyniki na mapie
meteo_imgw - Pozwala pobrać dane meteorologiczne interwale godzinowym, dziennym lub miesięcznym o danej randze stacji (SYNOP / CLIMATE / PRECIP) dostępnych w kolekcji dane.imgw.pl.
- Dane hydrologiczne:
- hydro_imgw - Pobieranie danych hydrologicznych o rozdzielczości dobowej lub miesięcznej ze stacji dostępnych w repozytorium danepubliczne.imgw.pl.
- Dane radiosondażowe :
- sounding_wyoming - Pobieranie pomiarów pionowych profil atmosfery (danych radiosondażowych)
Przykłady
Pokażemy, jak korzystać z naszego pakietu i przygotować dane do analizy przestrzennej z dodatkową pomocą paczek dplyr oraz tidyr. Najpierw pobierzemy 10 lat (2001-2010) miesięcznych obserwacji hydrologicznych dla wszystkich dostępnych stacji i automatycznie dodają ich współrzędne przestrzenne.
h = hydro_imgw(interval = "monthly", year = 2001:2010)
head(h)
#> id X Y Data PSNZWP KDNRZK MCROKH MCMSCH MCWSKEX
#> 1 149180010 NA NA 2000-11-01 KRZYZANOWICE Odra (1) 2001 1 1
#> 2 149180010 NA NA 2000-11-01 KRZYZANOWICE Odra (1) 2001 1 2
#> 3 149180010 NA NA 2000-11-01 KRZYZANOWICE Odra (1) 2001 1 3
#> 4 149180010 NA NA 2000-12-01 KRZYZANOWICE Odra (1) 2001 2 1
#> 5 149180010 NA NA 2000-12-01 KRZYZANOWICE Odra (1) 2001 2 2
#> 6 149180010 NA NA 2000-12-01 KRZYZANOWICE Odra (1) 2001 2 3
#> MCSTAN MCPRZP MCPTMP MCMSCK
#> 1 108 19.8 NA 11
#> 2 149 38.7 NA 11
#> 3 188 60.1 NA 11
#> 4 118 23.7 NA 12
#> 5 138 32.3 NA 12
#> 6 158 42.5 NA 12Zmienna MCWSKEX reprezentuje etykietę ekstremum, gdzie
“1” oznacza minimum, “2” oznacza średnią, a “3” maksimum. 1
Analizy hydrologiczne często koncentrują się na jednej grupy zjawisk,
np. związanych z przepływami maksymalnymi. W tym celu pozostaną w ramce
danych tylko wartości przepływów maksymalnych oraz kolumny zawierające
interesujące nas informacje, tj. identyfikator stacji - id,
rok hydrologiczny (MCROKH), szerokość geograficzną
X i długość geograficznąY.
Następnie obliczymy średnią maksymalną wartość przepływu na stacjach
w każdym roku za pomocą dplyr::summarise(), oraz
rozdzielimy dane według roku używając spread () aby uzyskać
roczne średnie maksymalne przepływy (MCPRZP) w kolejnych
kolumnach.
h2 = h %>%
dplyr::filter(MCWSKEX == 3) %>%
dplyr::select(id, PSNZWP, X, Y, MCROKH, MCPRZP) %>%
dplyr::group_by(MCROKH, id, PSNZWP, X, Y) %>%
dplyr::summarise(srednie_roczne_Q = round(mean(MCPRZP, na.rm = TRUE), 1)) %>%
spread(MCROKH, srednie_roczne_Q)| id | PSNZWP | X | Y | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 149180010 | KRZYZANOWICE | NA | NA | 200.5 | 147.4 | 87.9 | 109.2 | 170.6 | 226.9 | 152.9 | 131.0 | 160.9 | 461.1 |
| 149180020 | CHALUPKI | NA | NA | 174.7 | 96.7 | 57.6 | 91.8 | 146.9 | 170.6 | 110.2 | 101.6 | 124.7 | 314.6 |
| 149180030 | LAZISKA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | 210.3 |
| 149180040 | GOLKOWICE | NA | NA | 4.5 | 2.0 | 1.7 | 1.7 | 2.5 | 3.3 | 2.1 | 1.7 | 2.2 | 8.6 |
| 149180050 | ZEBRZYDOWICE | NA | NA | 13.5 | 7.9 | 3.8 | 5.0 | 10.4 | 6.5 | 5.8 | 2.8 | 4.5 | 23.6 |
| 149180060 | CIESZYN | NA | NA | 57.2 | 57.7 | 29.8 | 26.8 | 65.4 | 60.7 | 54.7 | 33.0 | 34.7 | 135.0 |
Wynik pokazuje jak zmienia się maksymalna roczna średnia prędkość przepływu wody w ciągu dekady dla wszystkich dostępnych stacji w Polsce.
Możemy wynik zapisać do:
.csv przy pomocą funkcji:
write.csv(result, file = "result.csv").xlsx przy pomocą funckcji:
write.xlsx(result, file = "result.xlsx", sheetName = "Poland", append = FALSE)
To polecenie zapisuje nasz wynik do pliku:result.xlsxo nazwie arkuszaPoland. Argumentappend=TRUEdodaje arkusz do istniejącego pliku.xlsx. By zapisać dane do formatu.xlsxnajpierw należy zainstalować pakiet writexl przy pomocy komendyinstall.packages("writexl"), oraz dodać go do naszego środowiska:library(writexl).
library(sf)
library(tmap)
library(rnaturalearth)
library(rnaturalearthdata)
world = ne_countries(scale = "medium", returnclass = "sf")
h3 = h2 %>%
filter(!is.na(X)) %>%
st_as_sf(coords = c("X", "Y"), crs = 4326)
tm_shape(h3) +
tm_symbols(size = as.character(c(2001:2010)),
title.size = "Średni przepływ maksymalny") +
tm_facets(free.scales = FALSE, ncol = 4) +
tm_shape(world) +
tm_borders(col = "black", lwd = 2) +
tm_layout(legend.position = c(-1.25, 0.05),
outer.margins = c(0, 0.05, 0, -0.25),
panel.labels = as.character(c(2001:2010)))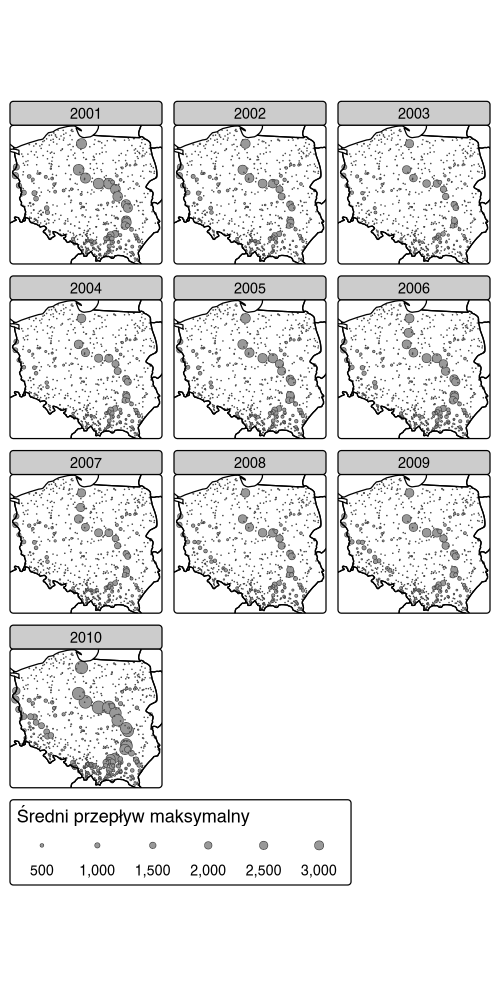
Więcej informacji na ten temat można znaleźć w zestawie danych
hydro_abbrev.↩︎